

背景:大多数目标检测受限于一小部分目标,无法检测各种各样的类别。和其他如分类任务相比,目标检测的数据集是相对有限的(yolov1检测(voc数据集20类)),这是因为在图像标记上比分类的标记要花费更多时间精力,因此不会像分类任务里头的Imagenet一样有几百万张标记好的图片(目标检测标记图片需要锚框,分类任务不需要)。
1. 网络结构
Yolov1:采用全连接层,将最后的卷积特征直接展平成一个向量,输出 7x7x30 大小的预测结果。全连接层的使用增加了计算复杂度,并且降低了空间位置感知能力。
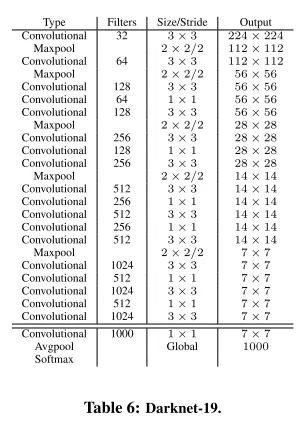
Yolov2:去掉了全连接层,改为全卷积网络,并引入了 1×1 卷积来调整通道数,增强了网络的灵活性和效率。此外,还在网络中加入了batch normolization,这有助于加速训练并提高模型的稳定性。
2. 预测框机制
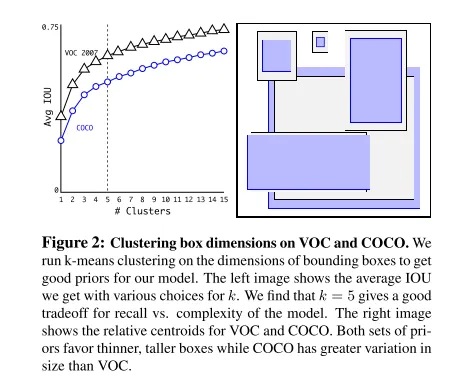
Yolov1:每个 grid cell 直接预测两个边界框的x, y, w, h,并且这两个框共用一个类别预测。
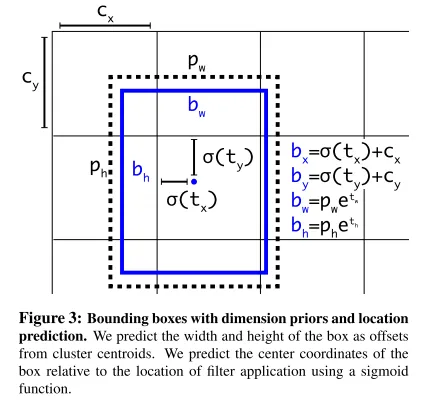
Yolov2:每个网格单元不再只预测两个边界框,而是预测多个与锚点尺寸相关的边界框。这些锚点是预先定义的,基于训练数据集中目标尺寸的分布。使用多个锚点可以提高对不同尺寸目标的检测能力。
3. 损失计算策略
只是计算策略不同,loss function还是使用MSE。
Yolov1:损失函数没有引入锚框的概念,直接预测边界框坐标。分类损失和定位损失直接相加。
Yolov2:在损失计算时,通过 IOU 找到与真实框最接近的预测框,然后基于此框来计算损失。锚框的引入使得 YOLOv2 更容易处理不同尺寸的物体。
4. 类别预测
Yolov1:每个 grid cell 的两个预测框共用一个类别预测,限制了检测的灵活性。
Yolov2:每个预测框有独立的类别预测,这使得 YOLOv2 可以在同一个 grid cell 内检测多种不同类别的物体。
5. 类别损失的优化
Yolov1:使用标准的 softmax 分类损失,类别数量多时,训练速度较慢。
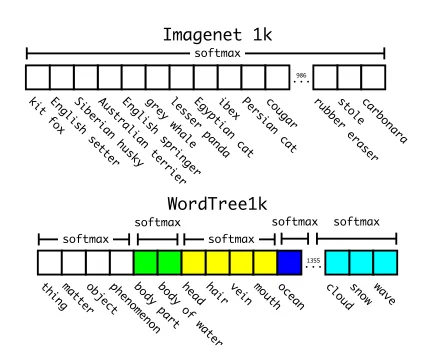
Yolov2:引入了 softmax tree,通过树状结构来优化多类分类,减少了计算复杂度,特别是在处理大规模分类任务时显得更为高效。
6. 其他改进
Yolov2引入了更高分辨率的图片进行训练(如 416×416),从而提高了检测小物体的效果。同时,YOLOv2 引入了多尺度训练,通过在训练中动态改变输入尺寸来增强模型的鲁棒性,使得它可以在不同分辨率下都能有良好的性能表现。