

作为目标检测领域的先驱,该方法对领域的影响是显著的。与单纯的图像分类任务相区别,目标检测不仅要求系统能够识别图像中的物体类别,还必须精确地定位出每个物体的边界框,增加了任务的复杂度。YOLO(You Only Look Once)算法采用锚框(anchor boxes)机制来进行对象检测,这是当前目标检测领域中一种广泛采纳的有效策略,其核心思想和实现细节值得我们进行深入探讨与学习。
网络结构:
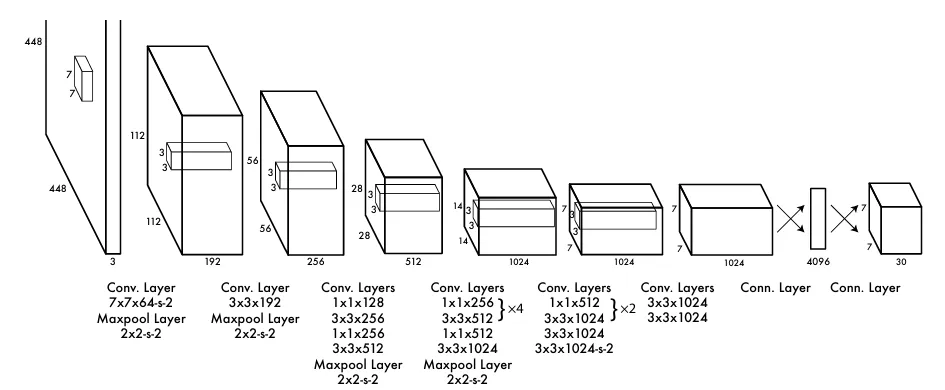
Yolov1采用了一种较为基本的网络架构,其设计受到了GoogleNet的启发。为了优化模型复杂度并加速计算过程,该模型采取了1×1卷积核来有效减少通道数量,继而与3×3卷积核相串联的方式。这一策略与GoogleNet中采用的机制有所差异,主要体现在Yolov1最终添加了两个额外的全连接层以整合特征信息,并且没有采用GoogleNet的多尺度卷积核最后合并的结构。这一初步的架构调整为后续Yolo系列的发展奠定了基础,激发了包括引入金字塔结构在内的多种关于主干网络(backbone)的改进探索,这些改进显著增强了模型在目标检测任务中的表现和效率。
损失:
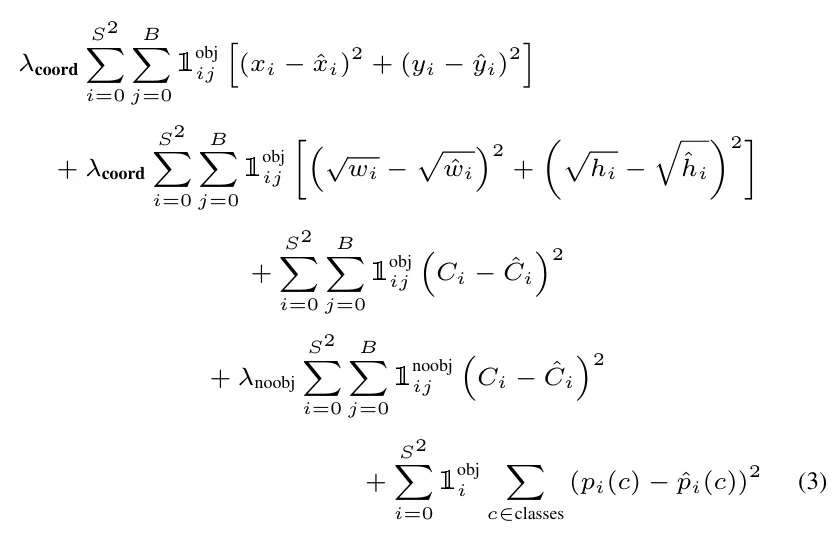
该过程分为三个阶段。首先,进行目标存在性评估的损失计算,该环节针对框是否封装有Object设计。具体实施时,若框内存在目标,则直接应用全额权重1进行计算;反之,为减轻无目标框对总损失的干扰,引入折扣因子0.5作为前缀调整其权重,并在此之后停止后续两项损失的计算。
其次,进入分类损失计算阶段。尽管每个单元(cell)配置了两套锚框,但分类任务仅执行一次,确保效率与精准度的平衡。此步骤采纳均方误差(MSE)作为优化指标,实现对分类结果的精确度量。
最后,关于锚框定位精度的损失计算,针对每7×7的单元区域,存在着两个预设锚框。通过精细比对,仅选取与真实边界框(ground-truth box)重叠度(IOU)最高的锚框参与损失计算。此步骤聚焦于中心坐标(x, y)及框的尺寸信息(w, h),同样运用均方误差(MSE)方法量化预测偏移,以此促进模型对锚框位置与尺度的精确学习。
下面为一部分损失的代码。
[code lang=”C”]
if(net.train){
float avg_iou = 0;
float avg_cat = 0;
float avg_allcat = 0;
float avg_obj = 0;
float avg_anyobj = 0;
int count = 0;
*(l.cost) = 0;
int size = l.inputs * l.batch;
memset(l.delta, 0, size * sizeof(float));
for (b = 0; b < l.batch; ++b){
int index = b*l.inputs;
for (i = 0; i < locations; ++i) {
int truth_index = (b*locations + i)*(1+l.coords+l.classes);
int is_obj = net.truth[truth_index];
for (j = 0; j < l.n; ++j) {
int p_index = index + locations*l.classes + i*l.n + j;
l.delta[p_index] = l.noobject_scale*(0 – l.output[p_index]);
*(l.cost) += l.noobject_scale*pow(l.output[p_index], 2);
avg_anyobj += l.output[p_index];
}
int best_index = -1;
float best_iou = 0;
float best_rmse = 20;
if (!is_obj){
continue;
}
[/code]
反向传播, 权重更新:
首先是最后一层,detection的反向传播,依据损失函数进行,而我们知道损失函数是MSE,故导数就从原来的2次降到1次。
[code lang=”C”]
void axpy_cpu(int N, float ALPHA, float *X, int INCX, float *Y, int INCY)
{
int i;
# N是进行计算的损失个数 INCX=INCY=1
# 若不包含Object,则N = 图片个数x49x2
# 若包含,N = 图片个数x49x2x(20+4×2+1×2)
for(i = 0; i < N; ++i) Y[i*INCY] += ALPHA*X[i*INCX];
}
[/code]
接着是卷积层,由于卷积层有权重,所以会多加一个权重更新。
[code lang=”C”]
void backward_convolutional_layer(convolutional_layer l, network net)
{
int i, j;
int m = l.n/l.groups;
int n = l.size*l.size*l.c/l.groups;
int k = l.out_w*l.out_h;
//激活函数的梯度 sigmoid求导
//这里其实有一个细节,为了节省内存,他没有保留激活函数前的输入值,而是将输出值进行计算梯度,
//这里是因为sigmoid的导数f'(x) = f(x)*(1-f(x)),故不需要将x保留,非常漂亮。
gradient_array(l.output, l.outputs*l.batch, l.activation, l.delta);
if(l.batch_normalize){
backward_batchnorm_layer(l, net);
} else {
backward_bias(l.bias_updates, l.delta, l.batch, l.n, k);
}
for(i = 0; i < l.batch; ++i){
for(j = 0; j < l.groups; ++j){
float *a = l.delta + (i*l.groups + j)*m*k;
float *b = net.workspace;
float *c = l.weight_updates + j*l.nweights/l.groups;
float *im = net.input + (i*l.groups + j)*l.c/l.groups*l.h*l.w;
float *imd = net.delta + (i*l.groups + j)*l.c/l.groups*l.h*l.w;
//对卷积核权重求梯度
if(l.size == 1){
b = im;
} else {
//将图像重塑
im2col_cpu(im, l.c/l.groups, l.h, l.w,
l.size, l.stride, l.pad, b);
}
//a为反向梯度,b为图像值,c是卷积核的梯度 做反卷积
gemm(0,1,m,n,k,1,a,k,b,k,1,c,n);
//对卷积层输入求梯度,要往前一层传 做反卷积
if (net.delta) {
a = l.weights + j*l.nweights/l.groups;
b = l.delta + (i*l.groups + j)*m*k;
c = net.workspace;
if (l.size == 1) {
c = imd;
}
gemm(1,0,n,k,m,1,a,n,b,k,0,c,k);
if (l.size != 1) {
col2im_cpu(net.workspace, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, imd);
}
}
}
}
}
void update_convolutional_layer(convolutional_layer l, update_args a)
{
float learning_rate = a.learning_rate*l.learning_rate_scale;
float momentum = a.momentum;
float decay = a.decay;
int batch = a.batch;
axpy_cpu(l.n, learning_rate/batch, l.bias_updates, 1, l.biases, 1);
scal_cpu(l.n, momentum, l.bias_updates, 1);
if(l.scales){
axpy_cpu(l.n, learning_rate/batch, l.scale_updates, 1, l.scales, 1);
scal_cpu(l.n, momentum, l.scale_updates, 1);
}
//权重衰减:调整权重的影响 ?
axpy_cpu(l.nweights, -decay*batch, l.weights, 1, l.weight_updates, 1);
//梯度更新:根据学习率调整权重
axpy_cpu(l.nweights, learning_rate/batch, l.weight_updates, 1, l.weights, 1);
//动量更新:加速收敛并平滑梯度
scal_cpu(l.nweights, momentum, l.weight_updates, 1);
}
[/code]
预测框预测机制:
[code lang=”C”]
void get_detection_detections(layer l, int w, int h, float thresh, detection *dets)
{
int i,j,n;
float *predictions = l.output;
//int per_cell = 5*num+classes;
for (i = 0; i < l.side*l.side; ++i){
int row = i / l.side;
int col = i % l.side;
for(n = 0; n < l.n; ++n){
int index = i*l.n + n;
// 存储顺序:先分类再置信度最后box坐标
int p_index = l.side*l.side*l.classes + i*l.n + n;
// 该框有无目标
float scale = predictions[p_index];
int box_index = l.side*l.side*(l.classes + l.n) + (i*l.n + n)*4;
box b;
b.x = (predictions[box_index + 0] + col) / l.side * w;
b.y = (predictions[box_index + 1] + row) / l.side * h;
b.w = pow(predictions[box_index + 2], (l.sqrt?2:1)) * w;
b.h = pow(predictions[box_index + 3], (l.sqrt?2:1)) * h;
dets[index].bbox = b;
dets[index].objectness = scale;
for(j = 0; j < l.classes; ++j){
int class_index = i*l.classes;
# 通关是否有目标以及分类的结果相乘是否超过阈值来确定该框最后的预测
float prob = scale*predictions[class_index+j];
dets[index].prob[j] = (prob > thresh) ? prob : 0;
}
}
}
}
[/code]
接下来,做一个叫做O(n²)的非最大抑制(NMS)步骤,它的作用是把那些大小差不多、靠得太近的框框都筛选掉,留下不重叠的部分。这个过程大概就是预测要做的事情。
实验对比:
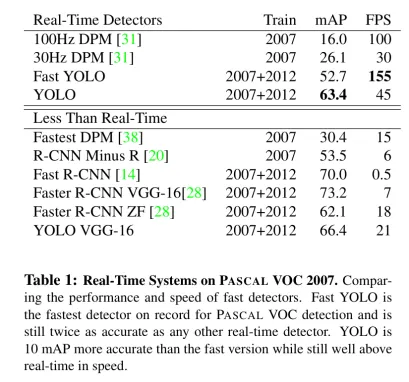
第一个对比实验是想证明实时性yolo确实有提高,在精度方面也有所提高在实时检测中,在非实时检测,也就是backbone变复杂后,效果其实没那么明显,准确度并没fast rcnn高。


在两者的对比分析中,YOLO 显著优势在于其能有效减少对背景的误检,这一成就部分归因于其采用的锚框数量相对fast rcnn模型较少,从而减轻了背景噪声的影响。然而,YOLO在定位精度(loc)方面表现出较多误差,主要是因为该模型在处理不同尺度目标时,难以实现高度精确的边界框拟合。这一问题根源可追溯至其锚框与实际对象框之间的匹配损失机制,表明了在尺度变化适应性上的局限性。
另一方面,fast rcnn在检测准确率方面展现出优越性能,这直接得益于其多框检测策略以及双阶段(double-stage)的处理流程。fast rcnn通过初步区域提议而后进行精细分类与定位,这样的设计有利于提高对复杂场景中目标识别的精确性。
不足之处:
首先,在处理多目标共享同一中心点的场景中,YOLO算法面临识别能力的局限。根本原因在于其架构设计:每个网格(cell)仅生成两个预设的锚框(anchor boxes),且这两个锚框共用一个分类输出。这意味着,即便多个目标中心聚集于同一网格内,该机制也只能提供单一的分类预测,从而难以有效区分和定位这些密集目标。
其次,YOLO依赖于激进的下采样策略以提取图像特征,这导致其在处理不同尺度对象时的适应性受限。具体而言,由于下采样过程中细节信息的丢失,模型对于目标尺寸和比例的变化敏感度较高,换言之,当目标的长宽比发生较大变化时,模型的检测性能显著下降,难以稳定地识别出这些变化的目标。
最后,在损失函数的设计上,YOLO对大小目标的优化存在不平衡。当大目标与小目标的定位误差(以交并比IOU衡量)相同时,小目标的实际定位损失影响更为显著。这种不均衡导致在训练过程中,小目标的定位精度提升不如大目标,这也是YOLO在定位精度(loc)方面相较于Fast R-CNN显示劣势的一个重要因素。
补充:
高层框架如 PyTorch 提供了极大的便利性和开发效率,适合模型训练和快速迭代;而 C/C++ 代码在推理阶段可以通过手写优化实现高效性能。
对于大多数应用,建议在训练阶段使用高层框架,在推理阶段使用优化的高性能库C++或手写优化代码,以兼顾开发效率和运行性能。