背景:2017年发表的Transformer,在NLP领域很受欢迎。但在计算机视觉领域,CNN仍占据主导地位。作者受Transformer的启发,尝试将Transformer最小限度的修改下应用到视觉任务中。
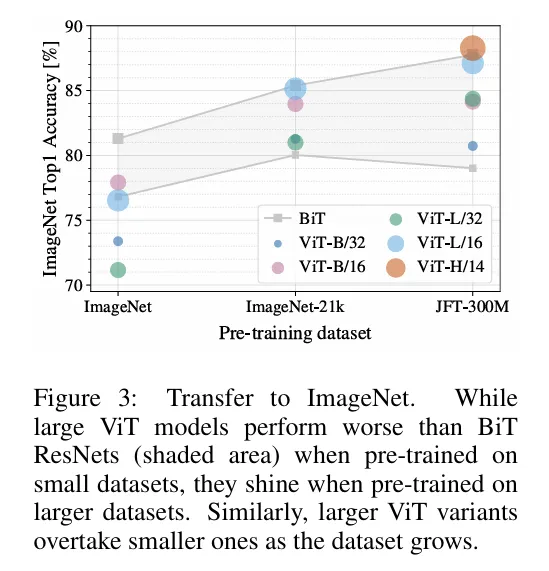
由于Transformer采用的是token序列形式,所以模仿该类型。将图片切割成一个个patch,经过一个线性全连接和添加位置编码后进入Transformer。采用无监督学习,在数据不大情况下预训练效果没有Resnet好,在数据量足够时VIT取得不错的效果。作者给出解释是先验知识不足。需要数据大来弥补。
网络模型:
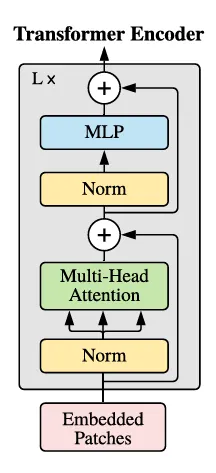
1.Transformer前和后


2.Transformer
采用的是多头自注意力。下面解释注意力机制以及Mutli-Head。利用注意力机制,首先是注意力汇聚从输入到输出。下图基本描述了基本流程,其中a为注意力评分函数。
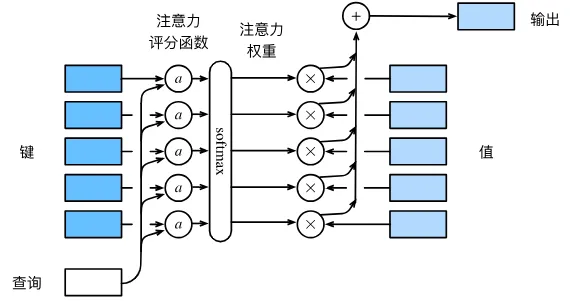

上面介绍了注意力汇聚函数,根据上述公式,还差一个注意力评分函数。一般来说,有加性注意力以及缩放点积注意力。

与其单独使用一个自注意力汇聚,借鉴Inception思想,利用多个自注意力汇聚,学习不同的行为,然后将不同的行为进行整合,捕捉序列或者图像各种范围的依赖关系。因此,多头注意力利用量这一点,允许注意力机制组合使用查询,键和值的不同子空间表示。
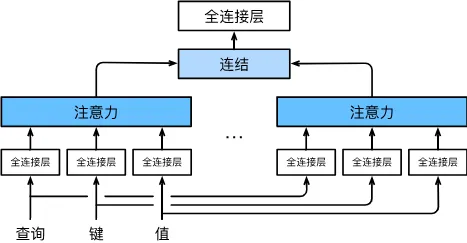
如图所示,独立学习h组不同的线性投影来变换查询,键和值。紧接着并行计算各自自注意力汇聚,最后拼接并通过另一个线性投影变换后输出。这就是多头注意力实现过程。每一个注意力汇聚被称为一个头。
补充:在自注意力机制中,计算注意力权重需要比较查询和键的相似性。通过不同的线性变换,模型可以学习到不同的表示,使得注意力机制更加灵活和有效。
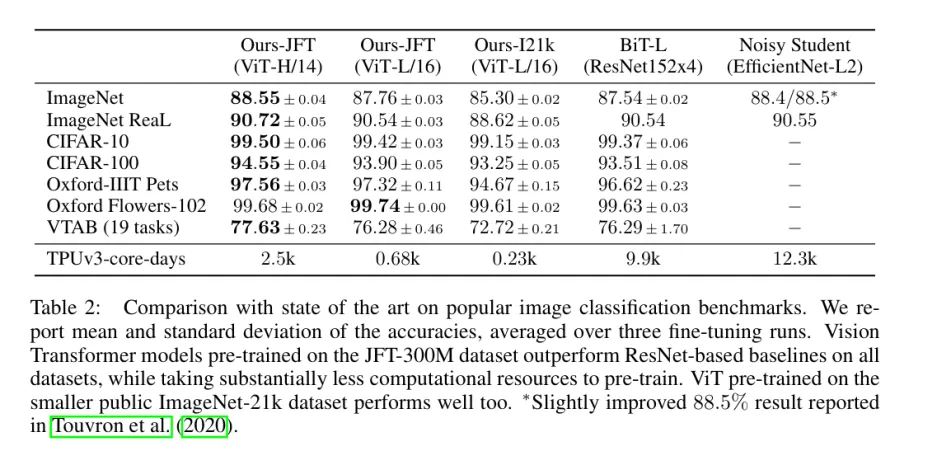
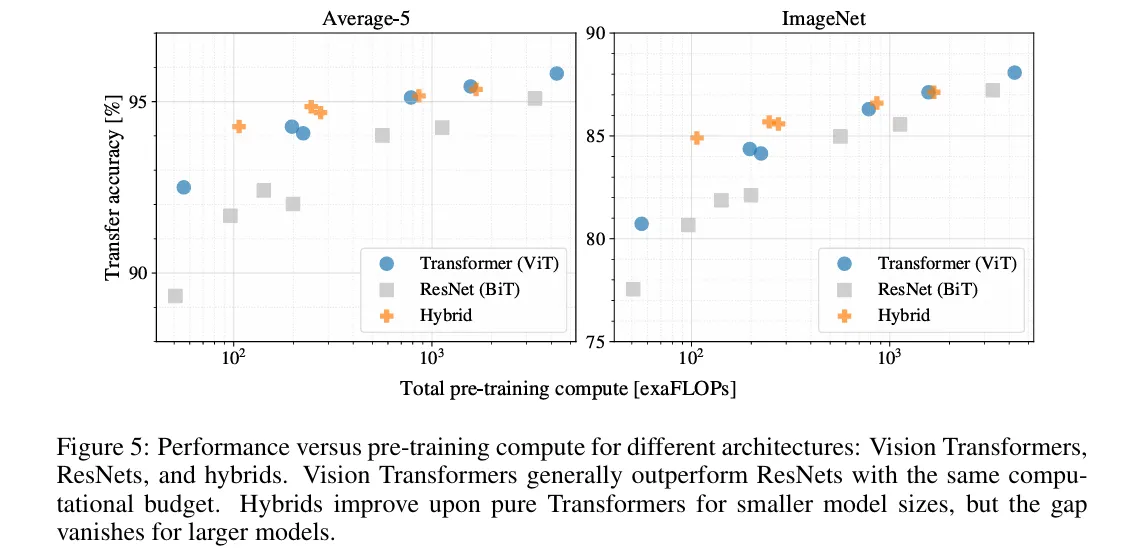
实验结果:
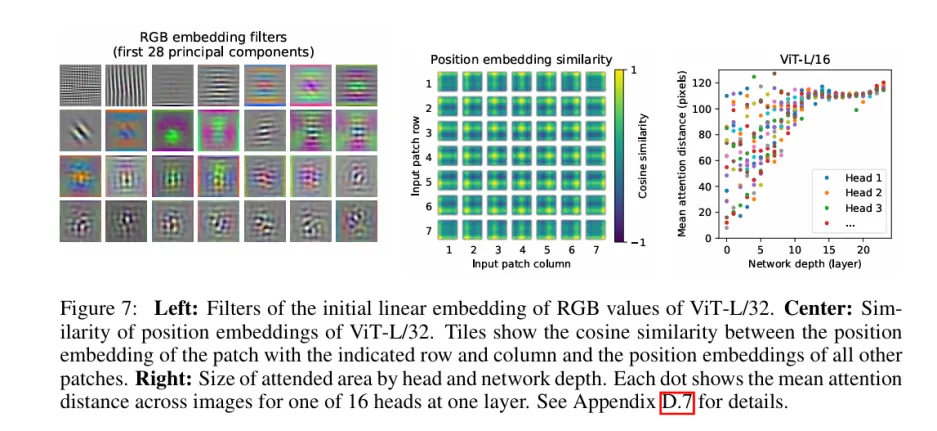
左边是从图像块铺平成向量转化为嵌入向量维度时经过的线性投影矩阵。线性投影矩阵中的每一行或一列可以看作是一个过滤器,它将输入图像块的像素值转换为嵌入向量的一部分。这个过滤器经过重塑后可以变成图像。这些过滤器是线性投影矩阵的组成部分。
中间是嵌入位置编码的余弦相似度,相似性矩阵显示了不同位置嵌入之间的相似性。49个7×7相似性矩阵。
最后是网络不同深度不同头的平均注意力距离。对于每一个头,每个位置,根据注意力权重计算加权平均位置,之后计算所有位置的注意力距离取平均就是该头的平均注意力距离。