

背景:
VIT打破了Transformer使用的局限性,将其应用到CV。为了解决VIT在训练高精度图片(即token数多)复杂度过高以及部分检测目标过于小导致检测精度不高问题,作者借助CNN的局部卷积扩大感受野提取特征,结合Transformer全局的特征学习,提取了Shift-Windows-Transformer。
1.网络结构图
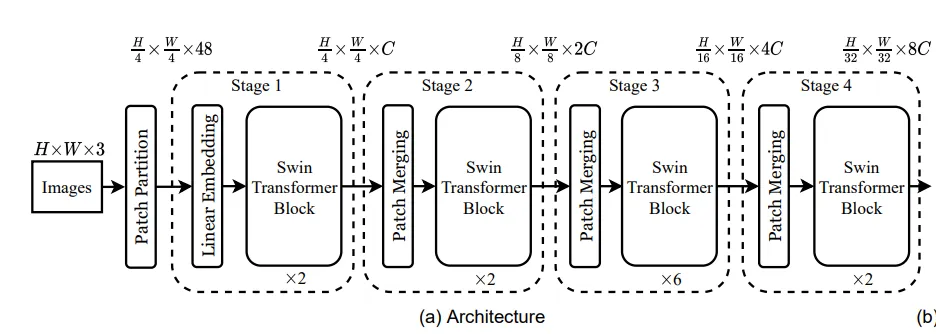
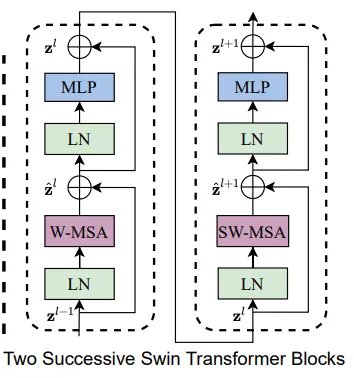
一开始先将图片切成patch并进行嵌入向量维度线性投影,之后进入2个Block,这两个区别在于一个使用W-MSA,另一个使用SW-MSA,这也是图中的Block都为偶数的原因,每一使用一次W-MSA后会跟一个SW-MSA。之后进入下一个Stage,首先会进入Patch-merging,类似于空洞卷积。之后是重复以上过程,不同之处在于Block的个数以及每一个Stage中做自注意力的num_heads个数不同。
2.Swim-Transformer-Block
2.1 W-MSA
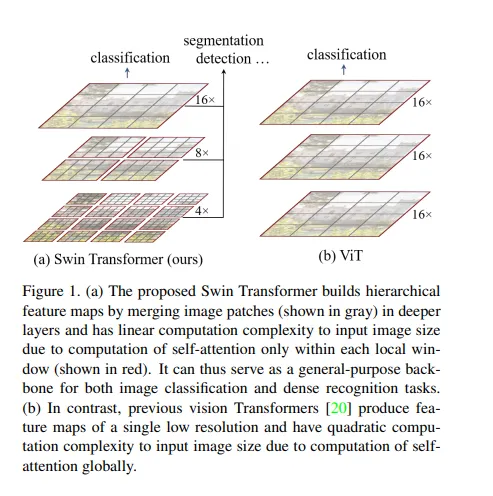
左边能够在更小范围内进行MSA,而VIT无法做到,这也是VIT的不足,对于一些比较小的目标物体无法检测到。与此同时,若使用VIT想将Patch_size变低,那么相应地其Patch个数增加,导致复杂度剧烈上升。SWIM是参考了CNN卷积的局部性,能够检测细小的目标物体。同时由于Patch减少,能够降低复杂度从平方变成线性。

2.2 SW-MSA
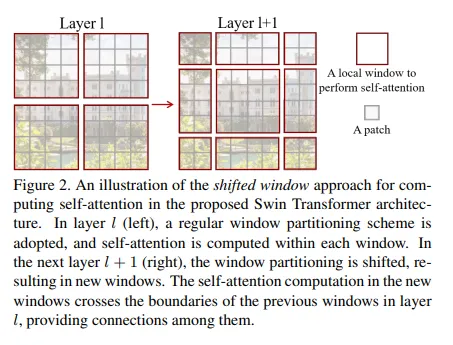
移动后的计算自注意力,对于不同窗口的尺寸,作者一开始想通过将小的窗口填充到MxM,之后使用掩码忽略填充过的Patch进行自注意力计算,但是这样一来2×2次计算变成3×3次了,复杂度按照上述推导的公式会增大至原来的2.25倍。所以作者使用了更高效的办法。
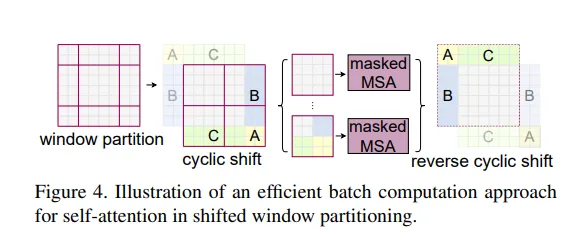
通过图中描述,计算次数还是2×2次窗口的自注意力计算。下图打印了图像四个边角落的掩码热力图。

有了以上MSA的变形,简单地两个BLOCK就形成了。前一个使用W-MSA,后一个使用SW-MSA。

3.实验结果
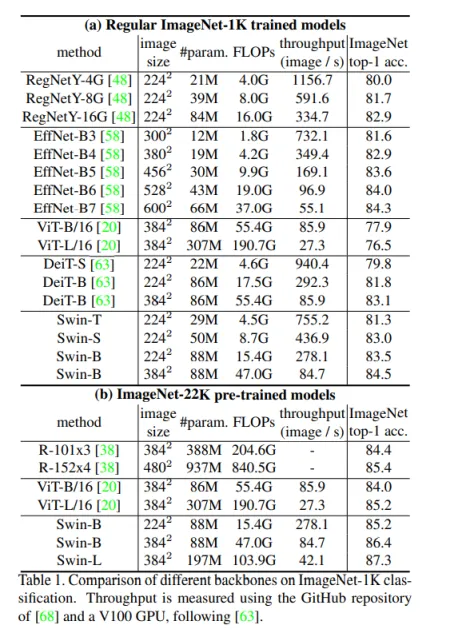
首先在图像分类任务中,对于相同的image_size情况下,例如和VIT对比,Swim通常是参数量较为少的一方,并且精度不错的一方。其次在模型做大情况下,精度随着复杂度上升跟着提升。
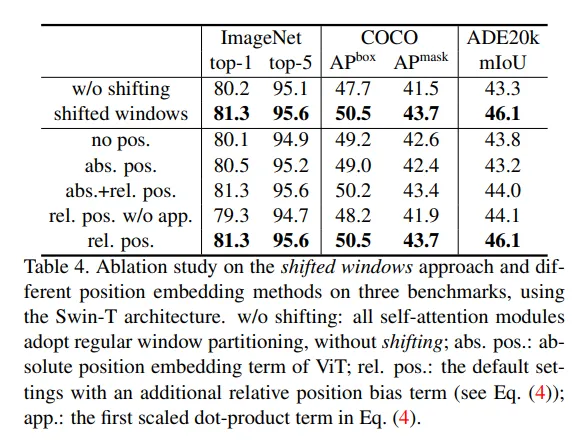
消融实验中,做了两组,一是对shift-window的使用,其次是位置编码的选择。
间隔一个像素采集,所以宽高会减半,同时在通道维度拼接后通道数会变成原来的4倍,之后再重塑并将通道数压缩至一半。这使得一次Patch_merging后宽高减半,通道数增加一半。