

Motivation:
1.传感器提供的3D骨骼点能够提供紧凑而稳定的表达能力。
2.GCNS难以捕捉到长距离关节相互作用以及长时间动态信息。

Conclusion: Transformer can capture all joints relation but can be efficient.
紧接着,问题来了,对于特定的动作,是否要对全部帧的全部关节点做自注意力呢?
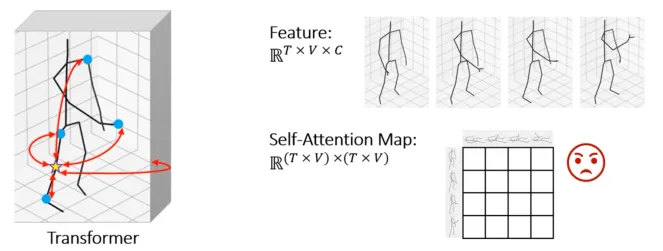
Conclusion: Specific joints in specific frames are more critical.
Method:
作者提出了一个关节和帧分区策略以及分区自注意力策略
其中分区自注意力策略有效捕捉骨骼及时态间的信息。由此有了分区的策略,总共有四种分法,是基于两种骨骼关系和两种时态关系。
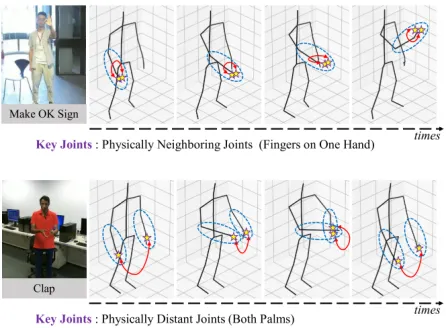 |
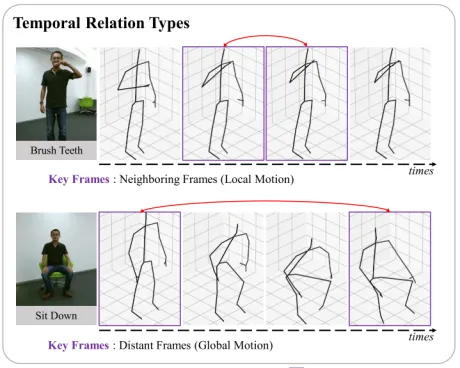 |
Model architecture:
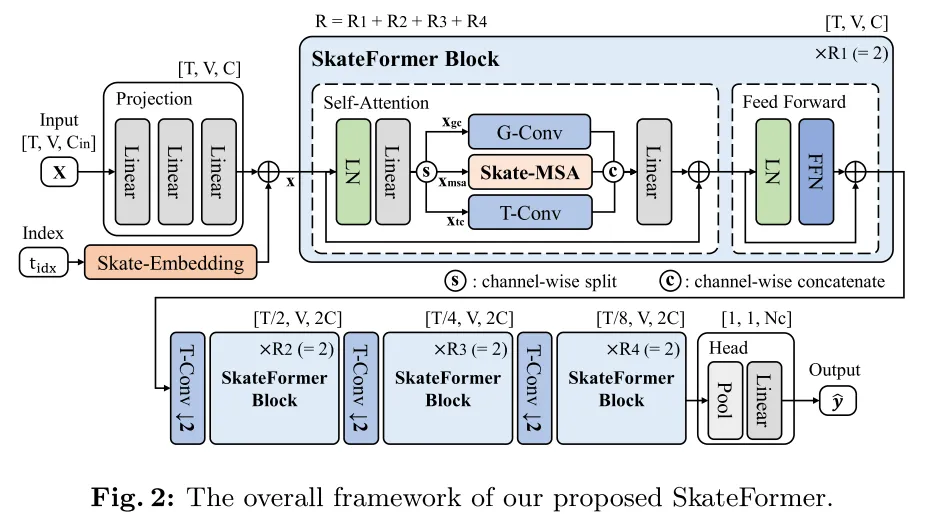
Skate-Embedding:
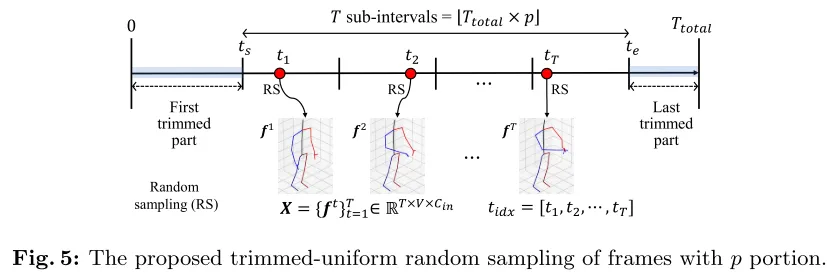
在原时间帧上进行裁剪率,裁剪率为1-P,利用固定的(不可学习的)时间索引特征和可学习的(不可固定的,可学习)骨架特征。
Skate-MSA:
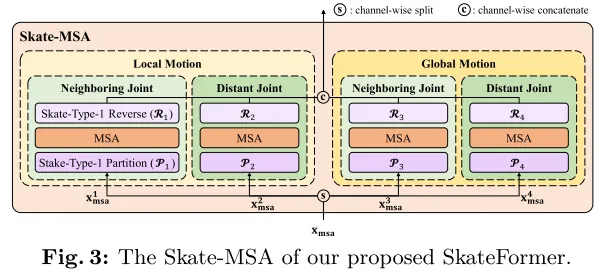
基于四种分区策略,将特征维度平分四份进行自注意力计算,结果再进行特征维度的拼接。总体来说,以上过程主体流程由下表达式呈现
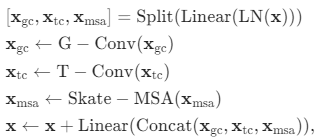
Partition and Reverse:
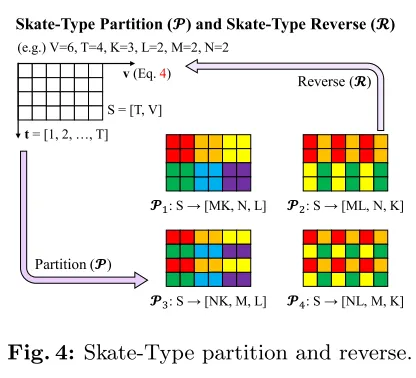
基于四种分区策略进行划分和重组,将计算复杂度降低为原来的48x
Experiment results:
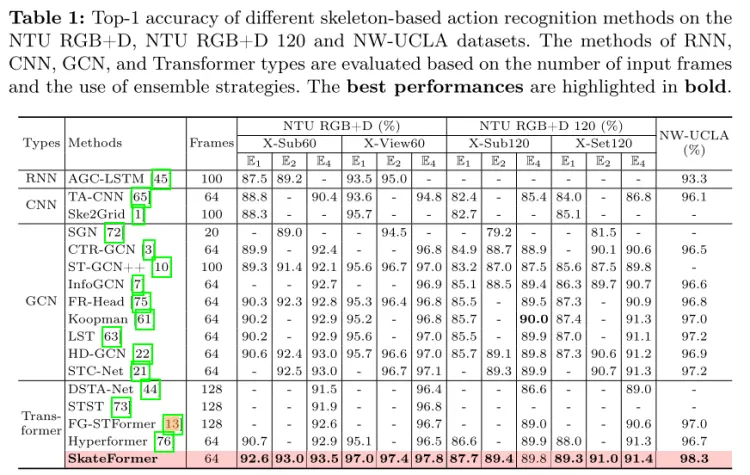
总结:这篇文章其实是swim-transformer类似思路,分区后做自注意力,这种迁移的思想值得学习。