
引言
目标检测是计算机视觉应用之一,具有代表性,它是目标分类问题的进一步延深。在Transformer流行之前,它使用了锚框来预测图片中的目标的类别。常见算法代表有Fast-rcnn,SSD,YOLO系列。本篇以SSD为主要算法进行描述。在描述之前,会先介绍几个计算机视觉领域常用的小技术图像增广和微调,之后介绍边缘框和锚框相关知识,最后讲SSD。
1.图像增广
足够多的数据集样本是深度学习网络的先决条件。图像增广正好能够扩充得到足够多的数据样本(通过对原始图片进行剪裁,翻转,改变颜色,加掩码等等),生成相似但不同的训练样本,从而扩大了训练集的数据规模。并且,图像增广能过减少模型对某些图像位置的依赖,一定程度提高模型的泛化能力。
2.微调(Fine tune)
训练网络需要一个初试权重,若采用预训练模型的参数,一定程度上能够较快学习到特征。这是一种迁移学习的思想,微调属于其中一种技巧。也是能提高模型泛化能力。下面介绍其主要步骤:
1.在源数据集如(ImageNet或COCO等)上训练预训练神经网络模型,也就是源模型。
2.创建一个新的同样结构的神经网络模型,也就是目标模型。并使用1训练后的权重作为初始权重(除了输出)。假定这些权重参数从源数据集学到的知识也将适用于目标数据集。
3.训练目标模型。
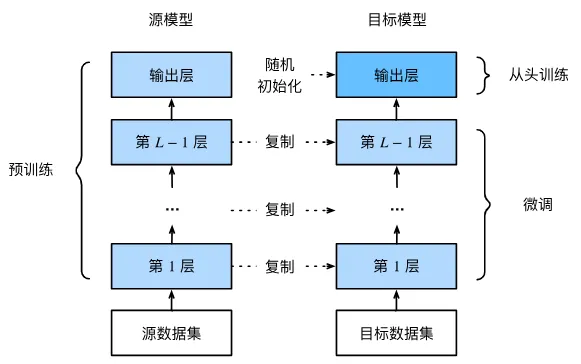
一般地,使用微调后学习率可以调低,相反地,一开始预训练模型时候的学习率可以调大。
3.边缘框和锚框
目标检测任务中,对训练集我们要标注目标所在位置,利用一个矩形边界框表示,即边缘框,通常可使用(labelImg库)进行手动标注。通常框的坐标为(x1,y1,x2,y2),其中(x1,y1)为左上角的坐标,(x2,y2)为右下角的坐标。
而锚框则是在训练和预测中使用,目标算法通常会在输入图像中采样大量区域,并在这些区域生成锚框并且判断是否包含感兴趣的目标,并调整锚框边界从而更准确接近目标的真实边界框。生成锚框有多种方法,这里不过多介绍。
有了锚框后,在训练中需要量化其与目标边界框的关系,这时候就需要计算其交并比(IOU),它用来衡量锚框与真实边界框之间的相似性。公式如下。
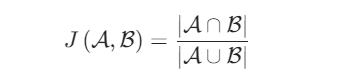
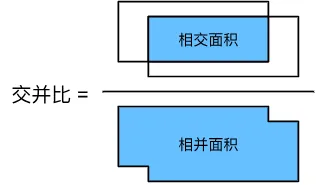
可以看到交并比取值范围在0到1之间,对于图像而言,通过下图可以更直观感受到IOU。
有了交并比,我们就可以在训练数据中标注锚框,以方便之后计算损失并反向传播更新权重参数。具体来说,在训练中,结合真实边界框可以标注锚框的类别(cls)和偏移量(offset),偏移量指的是真实边界框相对于锚框的偏移量。在预测中,则通过预测所有锚框的类别和偏移量,根据预测的偏移量调整它们的位置以获得预测的边界框,最后通过NMS(常用的非极大值抑制,后面介绍)来筛选符合特定条件的预测边界框。
标注锚框,首先是将真实边界框分配给锚框。步骤为
- 首先对于每一锚框,如果它与某个真实边界框的IOU大于或等于预设的正例阈值(例如0.5),则将该锚框分配给这个真实边界框。
- 剩下的锚框,对于每个真实边界框,找到与其IOU最大的锚框,并将该锚框分配给该真实边界框,即使此时该锚框可能已经分配给其他真实边界框。
- 前两步过后还没分配的锚框,如果它们的IOU小于预设的负例阈值(例如0.4),则将它们标记为背景。
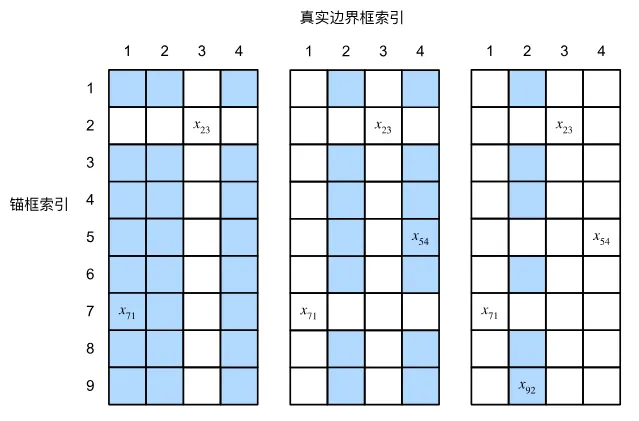
备注:x23>x71>x54>x92
当将真实边界框分配给锚框后,就可以对锚框标注类别(和真实边界框类别一致)并计算和真实边界框的偏移。之后返回锚框偏移,锚框掩码,锚框类别标签。
在预测时,就没有真实边界框,通常采用的是非极大值抑制(NMS)来输出,步骤如下:
- 在预测边界框B中,选择置信度得分(或分类得分)最高的边界框,该置信度得分对应的类别作为当前锚框的预测类别。
- 计算当前边界框与剩余所有边界框的IOU。
- 将与当前边界框的IOU大于预设阈值(例如0.5)的边界框移除。这些边界框被认为是与当前边界框重叠的重复检测结果.
- 重复b与c,直到没有边界框剩余或所有边界框的得分低于某个阈值。
4.SSD
SSD和YOLO都是属于单发多框检测模型设计,都是单阶段(single-stage)目标检测算法,它们直接从图像中预测目标的类别和边界框,而不需要额外的候选区域生成步骤。相反Fast-Rcnn是two-stage,基础网络可以采用VGG块或者Resnet,之后卷积不断降低宽高,对每一层特征图在每一个像素生成大小不同的锚框,并通过预测边界框的类别和偏移量来检测大小不同的目标。如下图所示。
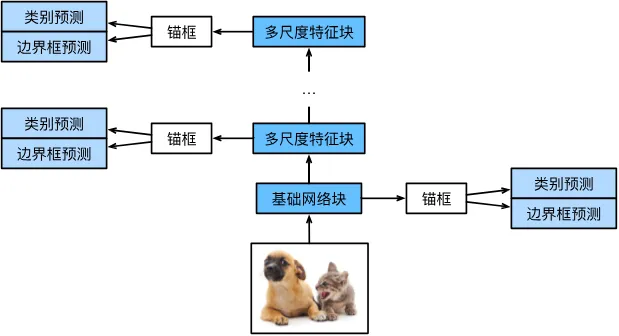
越接近顶部多尺度特征图较小,但具有较大的感受野,它们适合检测较少但较大的物体。相反,越接近原图适合检测较多但较小的物体。这是一个多尺度目标检测模型。YOLO和其区别很明显一点在于锚框初始化不一样,本次讲解较为简单但计算量复杂的SSD,这是由于它对每一张特征图的每一个像素生成不同size的锚框。
总结:目标检测和图片分类不同。图片分类的目标是识别整张图像的主要内容,并将其归类,输出是类别标签和对应的概率。常用的模型架构有VGG、ResNet等。目标检测不仅识别图像中的所有目标,还要定位它们的位置,输出是包含边界框、类别标签和置信度分数的列表。分类只需图像级标签,而目标检测需要边界框级标签,适用于更复杂的场景。