
1.Alexnet
首个实现了端到端预测。AlexNet是2012年提出的卷积神经网络,它显著提升了图像分类精度,通过引入ReLU激活函数、dropout和数据增强等技术,奠定了深度学习的基础。
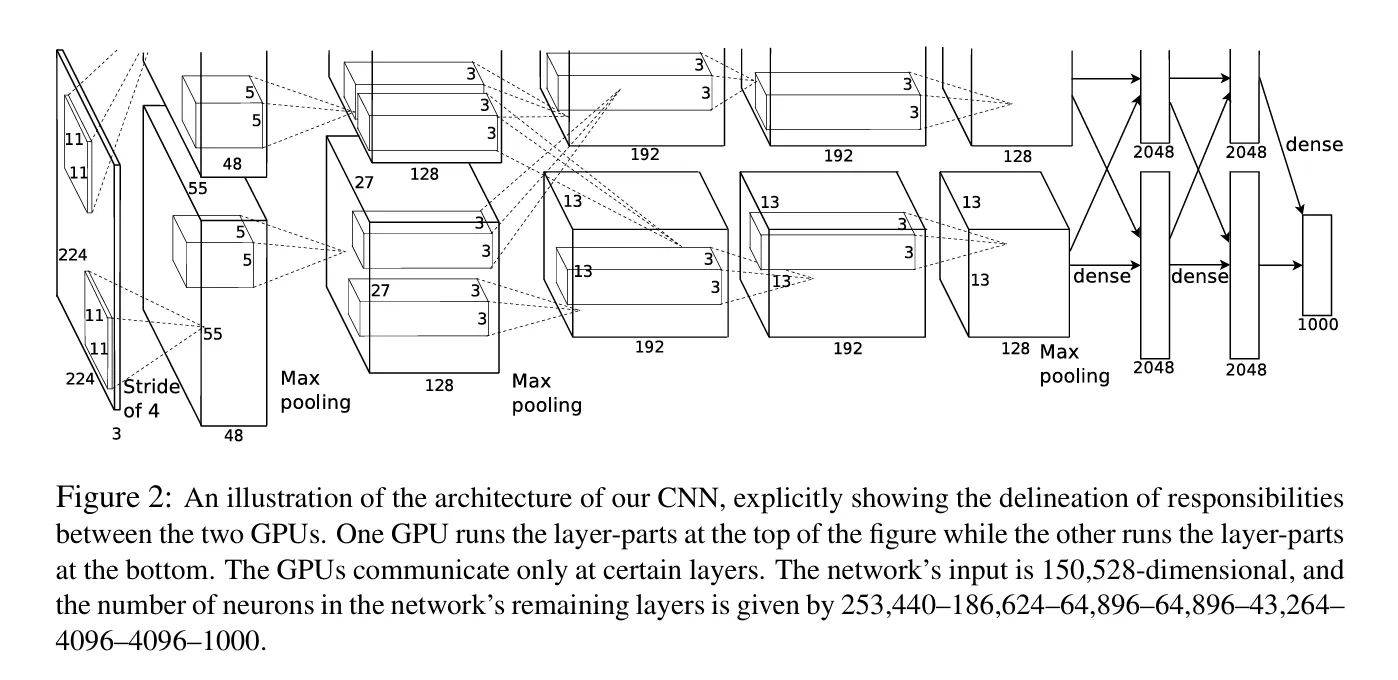
上图是采用论文作者双卡训练的过程。作者还在预防模型过拟合中使用了图像数据集增强以及Dropout(控制模型复杂度),提高了泛化能力。下图为该模型的实际过程图。由于输入图片较大(224×224),采用11×11卷积核捕捉特征。三个池化层都将长宽减半,降低模型复杂度。最后通过全连接层输入。属于典型的CNN网络。Alexnet使用了8层神经网络:5个卷积层和3个全连接层。
通过打印ALexnet每一层的参数量以及计算量,如下图所示,可以看到,参数量十分巨大,且大部分由全连接层贡献,而计算量大部分却由卷积层贡献。

具体可以理解为:如第二个全连接层,参数量为4096*4096+4096= 16.78M,而 仅第一个卷积层参数量为11*11*96*3 = 34.8K。而计算量第二个全连接层为4096*4096+4095=16.78M。第一个卷积层计算量为11*11*96*54*54*3+(11*11-1)*96*54*54*3=202M。
2.VGG
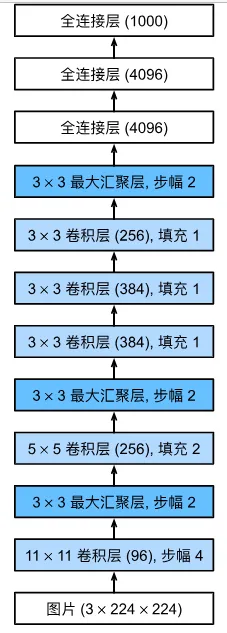
它在ALexnet基础上加深了网络深度。并提出了VGGBLOCK,每次由3×3卷积核,填充为1的卷积操作完成。卷积层用来增加通道数,提取特征。并通过最大池化层来降低图像长宽,增大感受野。下图为论文中的VGG模型结果图。
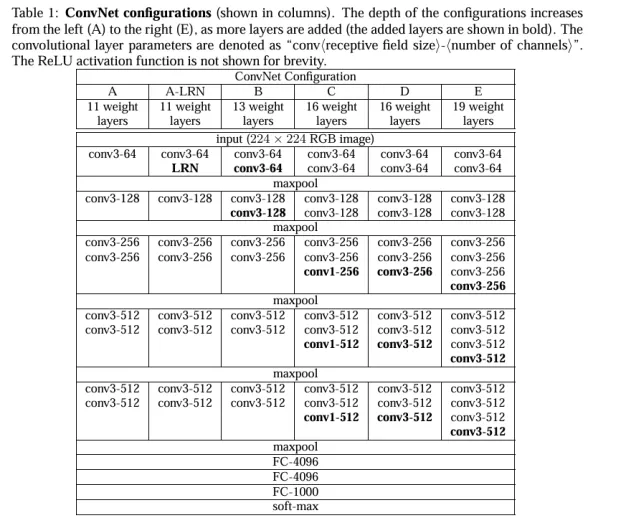
对于VGG11,由5个VGG块组成,前两个块各一次卷积,后三个块各2次卷积,加上三个全连接层,总共11层。比Alexnet更深,对应参数和计算量更大,准确率更高。
3.NIN
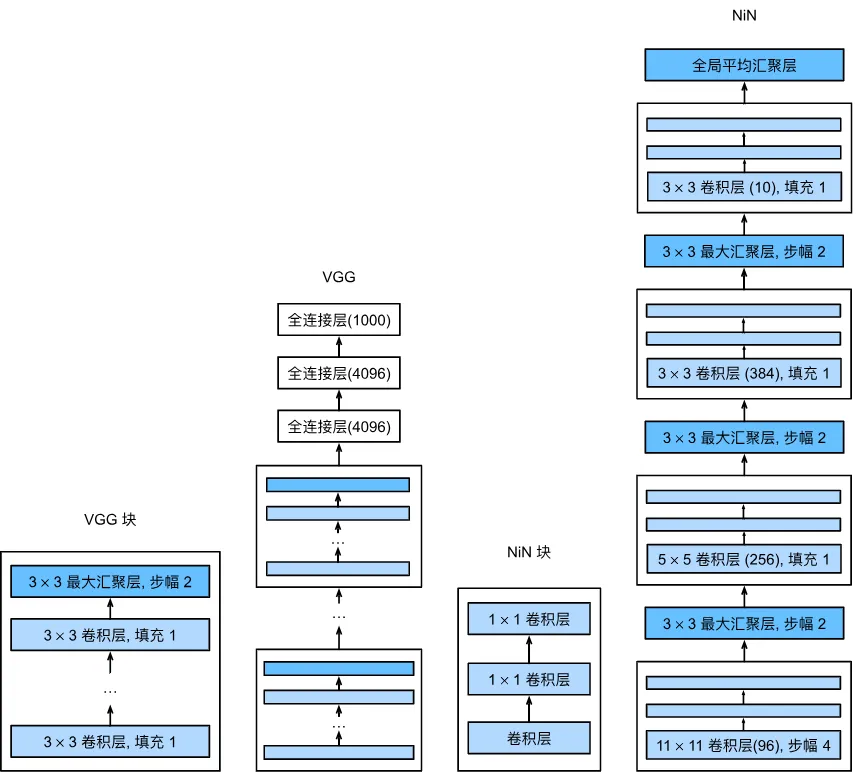
可以看到,和VGG一样,卷积层改变通道数,1×1全连接层能增加网络的非线性能力(通过增加更多的参数和激活函数),又能保持输入的空间结构不变。都是通过最大池化层来增加感受野。不一样地点在于最后不使用全连接层了,通过一个全局平均汇聚层来代表该输出,优点是能够显著减少参数量了,增强图像泛化能力。但也有缺点, 全局平均池化将每个特征图压缩成一个单一数值,可能会导致一些重要的细节信息丢失,特别是在需要精细化分类的任务中。
4.Googlenet
作者提出了一个Inception块,该块使用不同大小的卷积核做卷积后拼接一起作为输出。包括1×1,3×3,5×5。下图左边部分为原始版本的Inception块,它通道数太多,导致模型计算低效,于是作者改进采用1×1卷积核降低通道数,从而降低模型复杂度。这四条路径输入和输出长宽都一样,就是通道数不一样。四条路经输出的通道比是经过大量训练后得出的。
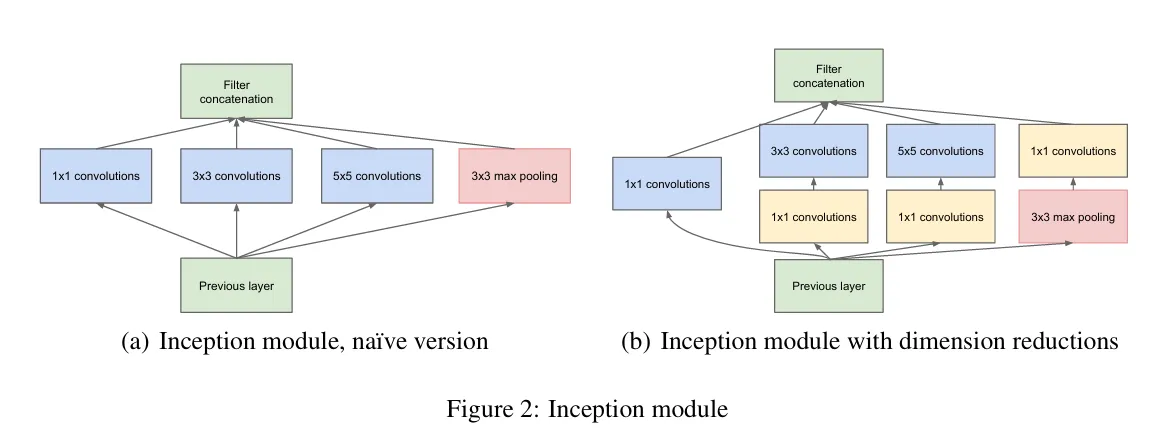
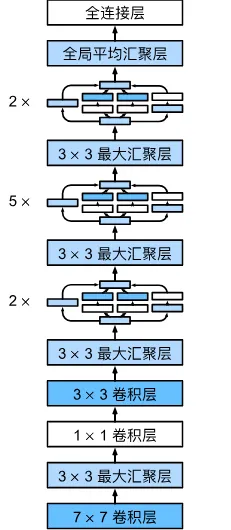
Googlenet采用了9个Inception块和全局平均池化层来生产估计值,Inception块之后进行合并再经过最大池化层降低图像长宽。全局平均池化和NIN一样,避免全连接层巨多的参数。
5.Resnet
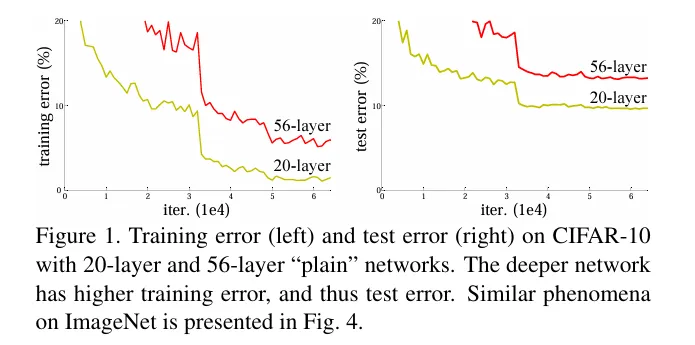
在Resnet之前,网络深度无法加深,一旦加深准确率就会下降。
作者提出残差块,核心思想是:每个附加层都应该更容易地包含原始元素作为其元素之一。 残差块接收输入 x,并输出一个变换后的值 F(x)+x。这一结构的跳跃连接使得梯度能够更快传递到前面的层,缓解了梯度消失问题,也因此加快收敛速度。这也使得网络层能够深入,解决了传统的深度网络在层数增加时会遇到性能下降的问题。
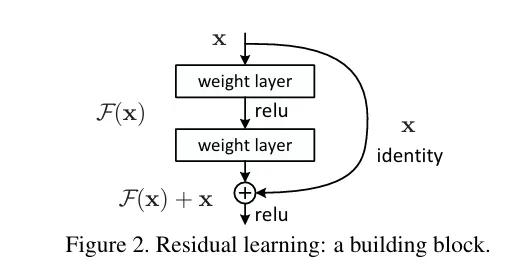
补充解释下resent有助于梯度稳定传播和网络有效训练。

6.Densenet
Densenet在Resnet基础上进行,Densenet是在通道维度上叠加输入与输出,而Resnet是将输入和输出相加。
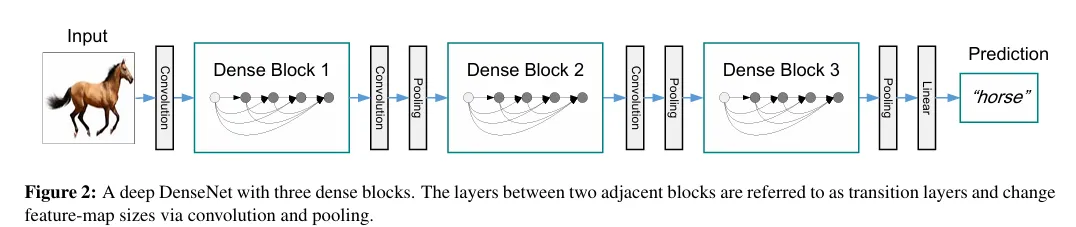
DenseNet由稠密块和过渡层交替连接组成。一个稠密块包含多个卷积块,每个卷积块使用相同数量的输出通道。稠密块通过特征复用来提取特征,每一层都接收之前所有层的输出作为输入,从而缓解了梯度消失问题,类似于ResNet的跳跃连接。
过渡层用于在网络中不同稠密块之间进行连接。通过压缩通道数(通常使用1×1卷积)和池化操作(如最大池化)来降低模型复杂度,同时增大感受野。这样设计不仅提高了特征提取效率,还有效地控制了网络参数的增长。
7.CSPnet
考虑到先前网络反向梯度传播计算量大导致消耗大量计算资源,作者对此进行改进,提出CSPnet(Cross Stage Partial Network)结构。
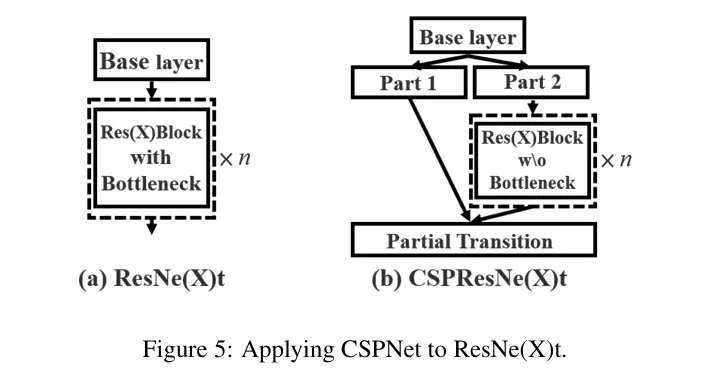
右边的改进算法中,将输入x0分成两部分进行输入,一部分直接连接输出端,通过这样降低反向传播计算量。
下面给出论文作者的推导过程,其中输入x0=[x0′ , x0”],在反向梯度传播中g0′单独计算,降低了过度重复的梯度计算信息。

以上内容参考花书。